Works
For all publications of our laboratory, we follow the convention of indicating all co-first authors by bolding their names in the authorship listing. Additionally, the corresponding authors will be noted with a dagger symbol (†).
At the end of this page, you can find the full list of publications and projects.
Reseach Area
- Multimodal Large Language Models,
- Generative Agents
- Diffusion Models
Project Highlights

Lumina-T2X is a unified framework for Text to Any Modality Generation.
Peng Gao, Le Zhuo, Dongyang Liu, Ruoyi Du, Xu Luo, Longtian Qiu, Yuhang Zhang, Chen Lin, Rongjie Huang, Shijie Geng, Renrui Zhang, Junlin Xi, Wenqi Shao, Zhengkai Jiang, Tianshuo Yang, Weicai Ye, He Tong, Jingwen He, Yu Qiao†, Hongsheng Li†

This repo proposes LLaMA-Adapter (V2), a lightweight adaption method for fine-tuning Instruction-following and Multi-modal LLaMA models.
Peng Gao†, Jiaming Han, Renrui Zhang, Ziyi Lin, Shijie Geng, Aojun Zhou, Wei Zhang, Pan Lu, Conghui He, Xiangyu Yue, Hongsheng Li†, Yu Qiao†

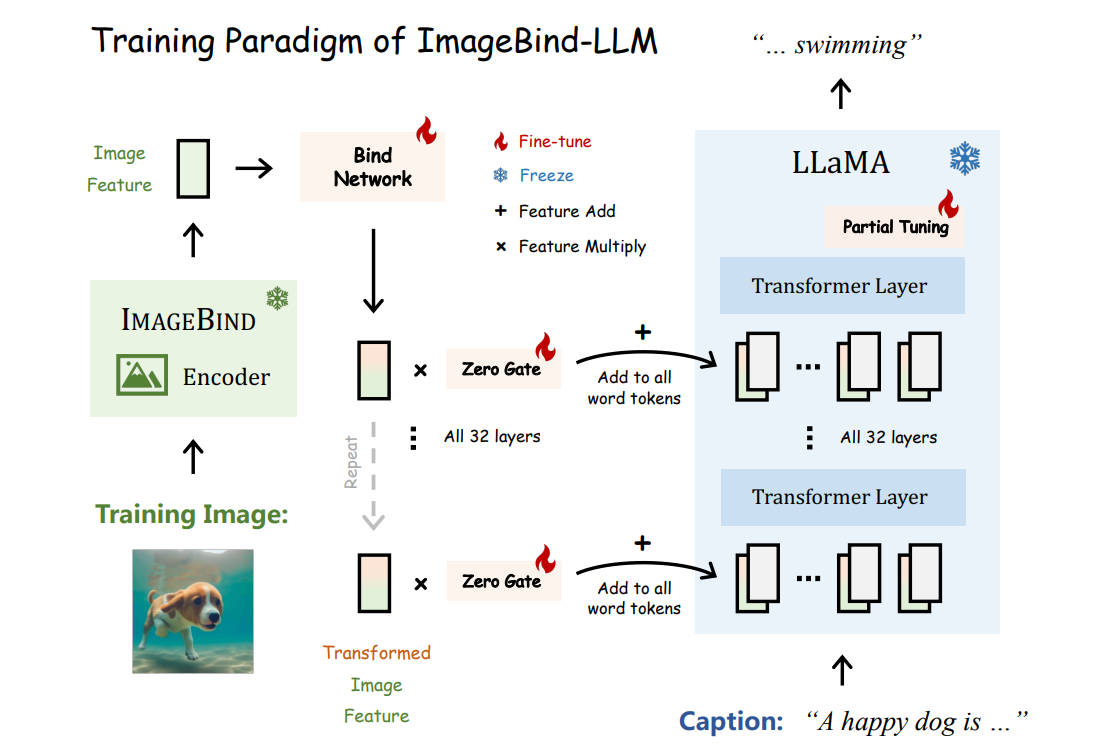
We present ImageBind-LLM, a multi-modality instruction tuning method of LLMs via ImageBind.
Jiaming Han, Renrui Zhang, Wenqi Shao, Peng Gao, Peng Xu, Han Xiao, Kaipeng Zhang, Chris Liu, Song Wen, Ziyu Guo, Xudong Lu, Shuai Ren, Yafei Wen, Xiaoxin Chen, Xiangyu Yue†, Hongsheng Li†, Yu Qiao†

LLaMA2-Accessory is an open-source toolkit for pre-training, fine-tuning and deployment of Large Language Models (LLMs) and mutlimodal LLMs.
Chris Liu, Ziyi Lin, Guian Fang, Jiaming Han, Yijiang Liu, Renrui Zhang, Peng Gao†, Wenqi Shao†, Shanghang Zhang†

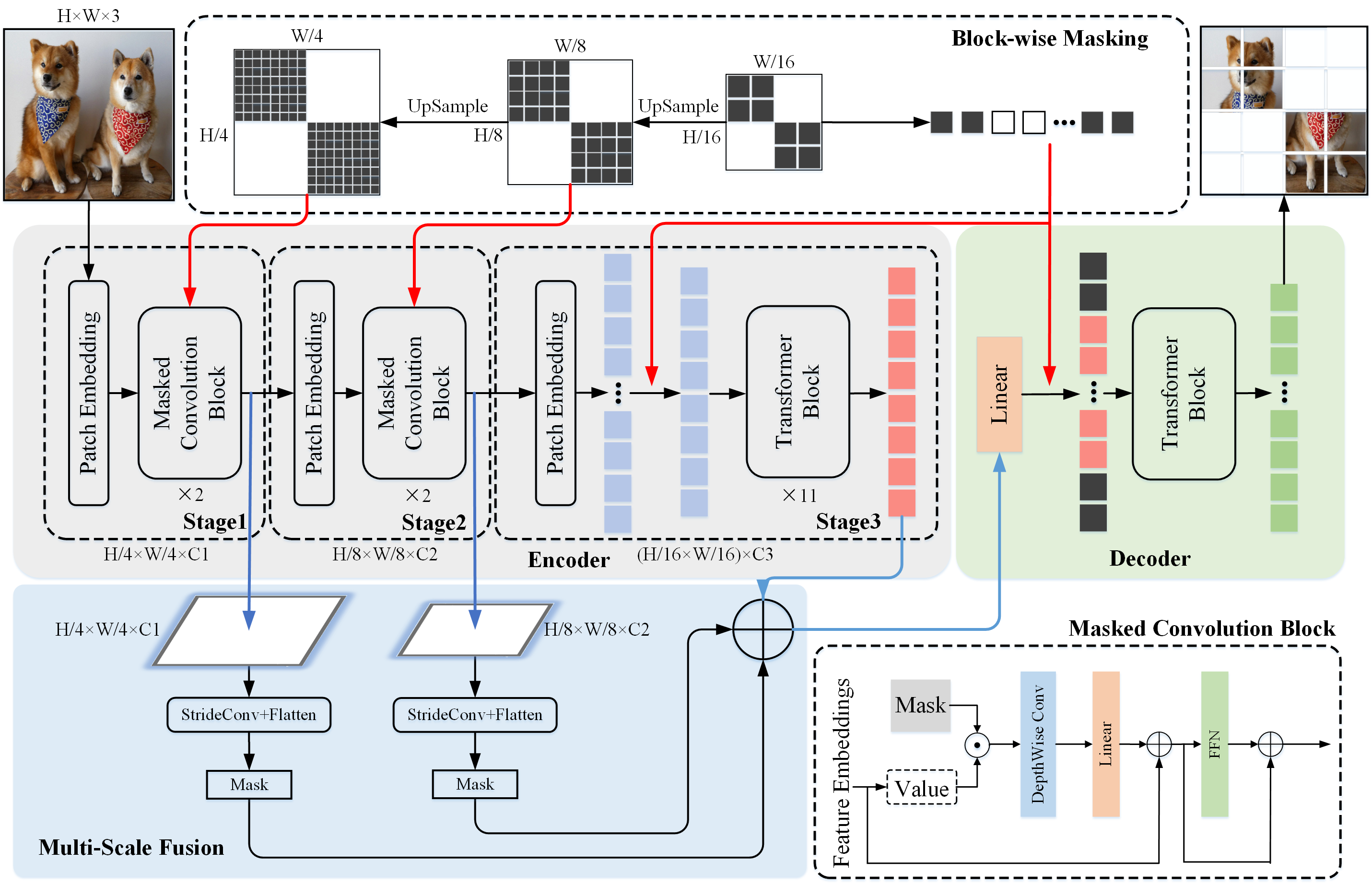
ConvMAE framework demonstrates that multi-scale hybrid convolution-transformer can learn more discriminative representations via the mask auto-encoding scheme.
Peng Gao, Teli Ma, Hongsheng Li†, Ziyi Lin, Jifeng Dai, Yu Qiao†

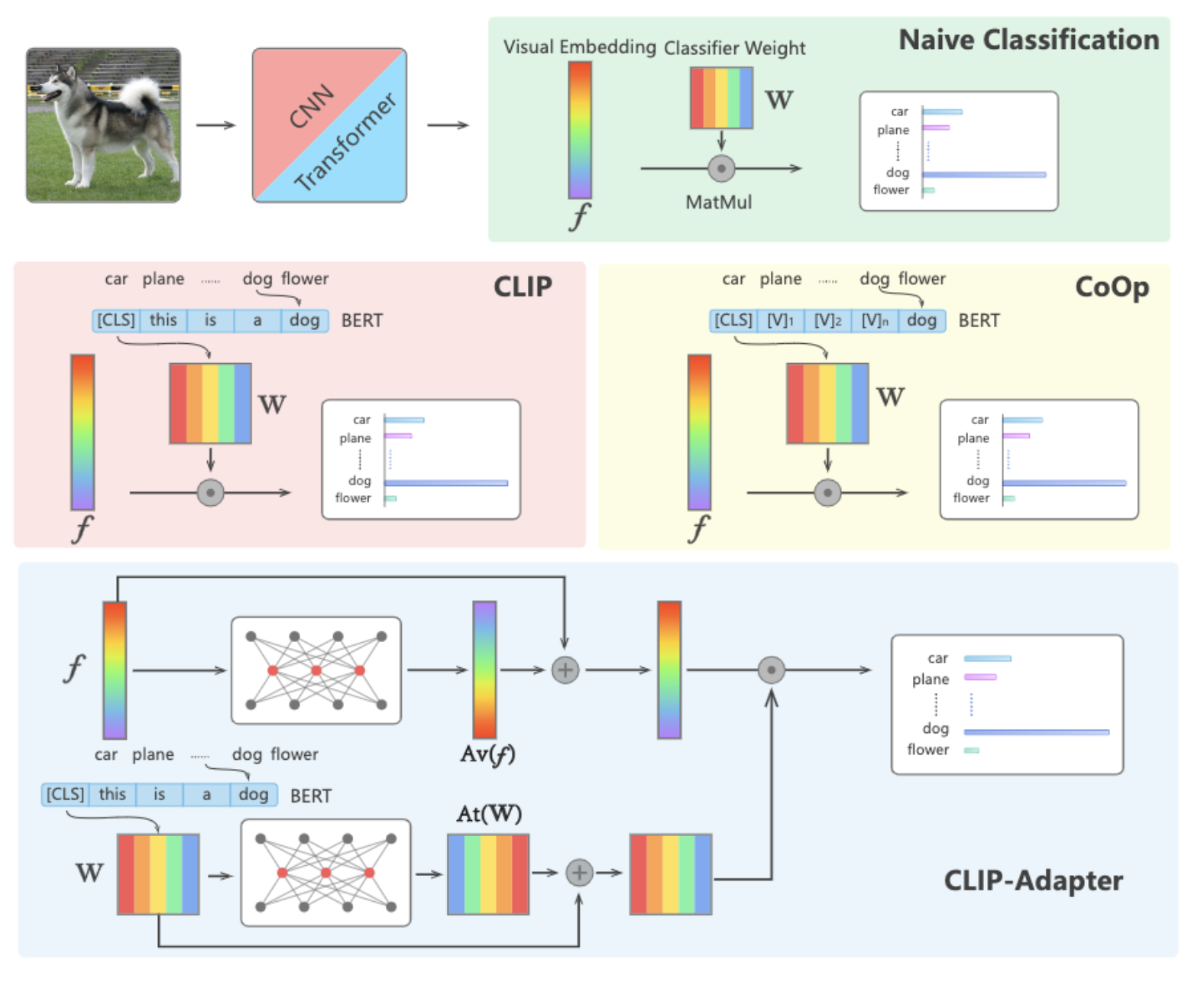
CLIP-Adapter is a drop-in module designed for CLIP on few-shot classfication tasks. CLIP-Adapter can improve the few-shot classfication of CLIP with very simple design.
Peng Gao, Shijie Geng, Renrui Zhang, Teli Ma, Rongyao Fang, Yongfeng Zhang, Hongsheng Li†, Yu Qiao†

All Research Projects 
Lumina-T2X: Transforming Text into Any Modality, Resolution, and Duration via Flow-based Large Diffusion Transformers
Peng Gao, Le Zhuo, Dongyang Liu, Ruoyi Du, Xu Luo, Longtian Qiu, Yuhang Zhang, Chen Lin, Rongjie Huang, Shijie Geng, Renrui Zhang, Junlin Xi, Wenqi Shao, Zhengkai Jiang, Tianshuo Yang, Weicai Ye, He Tong, Jingwen He, Yu Qiao†, Hongsheng Li†
LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
Renrui Zhang, Jiaming Han, Chris Liu, Peng Gao†, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li†, Yu Qiao†
LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model
Peng Gao†, Jiaming Han, Renrui Zhang, Ziyi Lin, Shijie Geng, Aojun Zhou, Wei Zhang, Pan Lu, Conghui He, Xiangyu Yue, Hongsheng Li†, Yu Qiao†
ImageBind-LLM: Multi-modality Instruction Tuning
Jiaming Han, Renrui Zhang, Wenqi Shao, Peng Gao, Peng Xu, Han Xiao, Kaipeng Zhang, Chris Liu, Song Wen, Ziyu Guo, Xudong Lu, Shuai Ren, Yafei Wen, Xiaoxin Chen, Xiangyu Yue†, Hongsheng Li†, Yu Qiao†
X-Accessory: An Open-source Toolkit for LLM Development
Chris Liu, Ziyi Lin, Guian Fang, Jiaming Han, Yijiang Liu, Renrui Zhang, Peng Gao†, Wenqi Shao†, Shanghang Zhang†
MCMAE: Masked Convolution Meets Masked Autoencoders
Peng Gao, Teli Ma, Hongsheng Li†, Ziyi Lin, Jifeng Dai, Yu Qiao†
CLIP-Adapter: Better Vision-Language Models with Feature Adapters
Peng Gao, Shijie Geng, Renrui Zhang, Teli Ma, Rongyao Fang, Yongfeng Zhang, Hongsheng Li†, Yu Qiao†
Container : Context Aggregation Network
Peng Gao, Jiasen Lu, Hongsheng Li†, Roozbeh Mottaghi†, Aniruddha Kembhavi†

SMCA : Fast convergence of detr with spatially modulated co-attention
Peng Gao, Minghang Zheng, Xiaogang Wang, Jifeng Dai, Hongsheng Li†

PointCLIP: Point Cloud Understanding by CLIP
Renrui Zhang, Ziyu Guo, Wei Zhang, Kunchang Li, Xupeng Miao, Bin Cui, Yu Qiao†, Peng Gao, Hongsheng Li†

Tip-Adapter: Training-free CLIP-Adapter for Better Vision-Language Modeling
Renrui Zhang, Wei Zhang, Rongyao Fang, Peng Gao†, Kunchang Li, Jifeng Dai, Yu Qiao†, Hongsheng Li†

PerSAM : Personalize Segment Anything Model with One Shot
Renrui Zhang, Zhengkai Jiang, Ziyu Guo, Shilin Yan, Junting Pan, Hao Dong, Peng Gao, Hongsheng Li†

All Publication by year
[CVPR 2024]Less is More: Towards Efficient Few-shot 3D Semantic Segmentation via Training-free Networks
Xiangyang Zhu, Renrui Zhang, Bowei He, Ziyu Guo, Jiaming Liu, Hao Dong, Peng Gao
arXiv
[CVPR 2024]OneLLM: One Framework to Align All Modalities with Language
Jiaming Han, Kaixiong Gong, Yiyuan Zhang, Jiaqi Wang, Kaipeng Zhang, Dahua Lin, Yu Qiao, Peng Gao, Xiangyu Yue
arXiv
[CVPR 2024]Masked AutoDecoder is Effective Multi-Task Vision Generalist
Han Qiu, Jiaxing Huang, Peng Gao, Lewei Lu, Xiaoqin Zhang, Shijian Lu
arXiv
[ICLR 2024]LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
Renrui Zhang, Jiaming Han, Chris Liu, Peng Gao, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, Yu Qiao
arXiv
[ICLR 2024]OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models
Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, Ping Luo
arXiv
[ICLR 2024]Personalize Segment Anything Model with One Shot
Renrui Zhang, Zhengkai Jiang, Ziyu Guo, Shilin Yan, Junting Pan, Xianzheng Ma, Hao Dong, Peng Gao, Hongsheng Li
arXiv
[ICLR 2024]BESA: Pruning Large Language Models with Blockwise Parameter-Efficient Sparsity Allocation
Peng Xu, Wenqi Shao, Mengzhao Chen, Shitao Tang, Kaipeng Zhang, Peng Gao, Fengwei An, Yu Qiao, Ping Luo
openreview
[CVPR 2023]Learning 3D Representations from 2D Pre-trained Models via Image-to-Point Masked Autoencoders
Renrui Zhang, Liuhui Wang, Yu Qiao, Peng Gao, Hongsheng Li
arXiv
[CVPR 2023]Parameter is Not All You Need: Starting from Non-Parametric Networks for 3D Point Cloud Analysis
Renrui Zhang, Liuhui Wang, Ziyu Guo, Yali Wang, Peng Gao, Hongsheng Li, Jianbo Shi
arXiv
[CVPR 2023]Stare at What You See: Masked Image Modeling without Reconstruction
Hongwei Xue, Peng Gao, Hongyang Li, Yu Qiao, Hao Sun, Houqiang Li, Jiebo Luo
arXiv
[CVPR 2023]Q-DETR: An Efficient Low-Bit Quantized Detection Transformer
Sheng Xu, Yanjing Li, Mingbao Lin, Peng Gao, Guodong Guo, Jinhu Lu, Baochang Zhang
arXiv
[CVPR 2023]Prompt, Generate, then Cache: Cascade of Foundation Models makes Strong Few-shot Learners
Renrui Zhang, Xiangfei Hu, Bohao Li, Siyuan Huang, Hanqiu Deng, Hongsheng Li, Yu Qiao, Peng Gao
arXiv
[ICCV 2023]Not All Features Matter: Enhancing Few-shot CLIP with Adaptive Prior Refinement
Xiangyang Zhu, Renrui Zhang, Bowei He, Aojun Zhou, Dong Wang, Bin Zhao, Peng Gao
arXiv
[ICCV 2023]MonoDETR: Depth-guided Transformer for Monocular 3D Object Detection
Renrui Zhang, Han Qiu, Tai Wang, Ziyu Guo, Xuanzhuo Xu, Ziteng Cui, Yu Qiao, Peng Gao, Hongsheng Li
arXiv
[ICCV 2023]PointCLIP V2: Prompting CLIP and GPT for Powerful 3D Open-world Learning
Xiangyang Zhu, Renrui Zhang, Bowei He, Ziyu Guo, Ziyao Zeng, Zipeng Qin, Shanghang Zhang, Peng Gao
arXiv
[ICCV 2023]SparseMAE: Sparse Training Meets Masked Autoencoders
Aojun Zhou, Yang Li, Jianbo Liu, Junting Pan, Renrui Zhang, Peng Gao, Rui Zhao, Hongsheng Li
[ACMMM 2023]SUG: Single-dataset Unified Generalization for 3D Point Cloud Classification
Siyuan Huang, Bo Zhang, Botian Shi, Peng Gao, Yikang Li, Hongsheng Li
arXiv
[TPAMI 2023]UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning
Kunchang Li, Yali Wang, Peng Gao, Guanglu Song, Yu Liu, Hongsheng Li, Yu Qiao
arXiv
[IJCV 2023]CLIP-Adapter: Better Vision-Language Models with Feature Adapters
Peng Gao, Shijie Geng, Renrui Zhang, Teli Ma, Rongyao Fang, Yongfeng Zhang, Hongsheng Li, Yu Qiao
arXiv
[IJCV 2023]Mimic before Reconstruct: Enhancing Masked Autoencoders with Feature Mimicking
Peng Gao, Renrui Zhang, Rongyao Fang, Ziyi Lin, Hongyang Li, Hongsheng Li, Qiao Yu
arXiv
[ECCV 2022]Tip-Adapter: Training-free Adaption of CLIP for Few-shot Classification
Renrui Zhang, Zhang Wei, Rongyao Fang, Peng Gao, Kunchang Li, Jifeng Dai, Yu Qiao, Hongsheng Li
arXiv
[ECCV 2022]Recurrent Bilinear Optimization for Binary Neural Networks
Sheng Xu, Yanjing Li, Tiancheng Wang, Teli Ma, Baochang Zhang, Peng Gao, Yu Qiao, Jinhu Lv, Guodong Guo
arXiv
[ECCV 2022]IDa-Det: An Information Discrepancy-aware Distillation for 1-bit Detectors
Sheng Xu, Yanjing Li, Bohan Zeng, Teli ma, Baochang Zhang, Xianbin Cao, Peng Gao, Jinhu Lv
arXiv
[ECCV 2022]Prototypical Contrast Adaptation for Domain Adaptive Semantic Segmentation
Zhengkai Jiang, Yuxi Li, Ceyuan Yang, Peng Gao, Yabiao Wang, Ying Tai, Chengjie Wang
arXiv
[ECCV 2022]Frozen CLIP Models are Efficient Video Learners
Ziyi Lin, Shijie Geng, Renrui Zhang, Peng Gao, Gerard de Melo, Xiaogang Wang, Jifeng Dai, Yu Qiao, Hongsheng Li
arXiv
[NeurIPS 2022]Point-M2AE: Multi-scale Masked Autoencoders for Hierarchical Point Cloud Pre-training
Renrui Zhang, Ziyu Guo, Rongyao Fang, Bin Zhao, Dong Wang, Yu Qiao, Hongsheng Li, Peng Gao
arXiv
[NeurIPS 2022]Q-ViT: Accurate and Fully Quantized Low-bit Vision Transformer
Yanjing Li, Sheng Xu, Baochang Zhang, Xianbin Cao, Peng Gao, Guodong Guo
arXiv
[NeurIPS 2022]MCMAE: Masked Convolution Meets Masked Autoencoders
Peng Gao, Teli Ma, Hongsheng Li, Ziyi Lin, Jifeng Dai, Yu Qiao
arXiv
[CVPR 2022]PointCLIP: Point Cloud Understanding by CLIP
Renrui Zhang, Ziyu Guo, Wei Zhang, Kunchang Li, Xupeng Miao, Bin Cui, Yu Qiao, Peng Gao, Hongsheng Li
arXiv
[ICLR 2022]UniFormer: Unifying Convolution and Self-attention for Visual Recognition
Kunchang Li, Yali Wang, Junhao Zhang, Peng Gao, Guanglu Song, Yu Liu, Hongsheng Li, Yu Qiao
arXiv
[NeruIPS 2021]Container: Context Aggregation Networks
Peng Gao, Jiasen Lu, Hongsheng Li, Roozbeh Mottaghi, Aniruddha Kembhavi
arXiv
[NeruIPS 2021]Dual-stream Network for Visual Recognition
Mingyuan Mao, Renrui Zhang, Honghui Zheng, Peng Gao, Teli Ma, Yan Peng, Errui Ding, Baochang Zhang, Shumin Han
arXiv
[ICCV 2021]Fast Convergence of DETR with Spatially Modulated Co-Attention
Peng Gao, Minghang Zheng, Xiaogang Wang, Jifeng Dai, Hongsheng Li
arXiv
[ICCV 2019]Multi-modality Latent Interaction Network for Visual Question Answering
Peng Gao, Haoxuan You, Zhanpeng Zhang, Xiaogang Wang, Hongsheng Li
arXiv
[CVPR 2019]Dynamic Fusion with Intra- and Inter- Modality Attention Flow for Visual Question Answering
Gao Peng, Zhengkai Jiang, Haoxuan You, Pan Lu, Steven Hoi, Xiaogang Wang, Hongsheng Li
arXiv
[ECCV 2018]Question-Guided Hybrid Convolution for Visual Question Answering
Peng Gao, Pan Lu, Hongsheng Li, Shuang Li, Yikang Li, Steven Hoi, Xiaogang Wang
arXiv
[Arxiv 2023]LVLM-eHub: A Comprehensive Evaluation Benchmark for Large Vision-Language Models Attention
Peng Xu, Wenqi Shao, Kaipeng Zhang, Peng Gao, Shuo Liu, Meng Lei, Fanqing Meng, Siyuan Huang, Yu Qiao, Ping Luo
arXiv
[Arxiv 2023]LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model
Peng Gao, Jiaming Han, Renrui Zhang, Ziyi Lin, Shijie Geng, Aojun Zhou, Wei Zhang, Pan Lu, Conghui He, Xiangyu Yue, Hongsheng Li, Yu Qiao
arXiv
[Arxiv 2024]Lumina-T2X: Transforming Text into Any Modality, Resolution, and Duration via Flow-based Large Diffusion Transformers
Peng Gao, Le Zhuo, Dongyang Liu, Ruoyi Du, Xu Luo, Longtian Qiu, Yuhang Zhang, Chen Lin, Rongjie Huang, Shijie Geng, Renrui Zhang, Junlin Xi, Wenqi Shao, Zhengkai Jiang, Tianshuo Yang, Weicai Ye, He Tong, Jingwen He, Yu Qiao, Hongsheng Li
arXiv